stable diffusion在线部署
AIGC之 AI 绘画
随着人工智能技术的发展与完善,AI Generated Content (AIGC,人工智能自动生成内容) 在内容的创作上为人们的工作和生活带来前所未有的帮助,具体表现在能够帮助人类提高内容生产的效率,丰富内容生产的多样性、提供更加动态且可交互的内容。
AIGC 相关技术可以在创意、表现力、迭代、传播、个性化等方面,充分发挥技术优势,打造新的数字内容生成与交互形态。在这两年AIGC在AI作画、AI 作曲、AI 作诗、AI写作、AI视频生成、 AI语音合成等领域持续大放异彩;尤其是近段时间火遍全网的AI绘画,作为用户的我们只要简单输入几个关键词几秒钟之内一幅画作就能诞生。
AI 绘画为产业界带来了巨大的生产力提升:文本生成图像(AI 绘画)是根据文本生成图像的的新型生产方式,相比于人类创作者,文本生成图像展现出了创作成本低、速度快且易于批量化生产的优势。
近期各个大厂的AI绘画产品也相继出炉,而对于个人使用者和喜欢尝鲜的开发者而言,最值得体验的两款AI绘画产品莫过于 Midjourney 和 Stable Diffusion;Midjourney 是一款商业AI绘画工具,借助于 Discord 服务平台快速普及,受到众多用户的追捧和喜爱;而 Stable Diffusion 则选择了走开源之路,并且在一些方面的出图潜力和Midjourney相比不相伯仲,受到广大开源爱好者的青睐。
目前,stable-diffusion-webui 成为GitHub上最为火热的一个 Stable Diffusion 部署代码,只要有一个带显卡(显存越大出图越快)的主机或者服务器就能完美运行这个代码,并且可以根据自己的喜好来组合各种有趣的视觉模型。
但是对于更多的个人用户而言,一个带显卡的服务器电脑成为阻碍他们部署个人 Stable Diffusion 的一大瓶颈,我们普通的创业者和开发者,有没有机会去训练和部署我们所看好领域的AIGC模型呢,答案是肯定的,在当下这个云服务时代,人人都有机会成为前沿的技术探索者。 最近受亚马逊云科技邀请在 Amazon SageMaker 平台进行技术实践,之前也一直苦于缺少合适的GPU服务器而难以快速部署属于自己的 Stable Diffusion这一困扰在遇到 Amazon SageMaker 之后烟消云散。
20分钟搞定 Stable Diffusion 模型在线服务部署
认识 Amazon SageMaker
Amazon SageMaker 是一项完全托管的机器学习服务:借助SageMaker的多种功能,数据科学家和开发人员可以快速轻松地构建和训练机器学习模型,然后直接部署至生产环境就绪的托管环境。SageMaker涵盖了ML 的整个工作流,可以标记和准备数据、选择算法、训练模型、调整和优化模型以便部署、预测和执行操作。
经过过去一周多的学习和实践体验,我发现这个平台简直就是为我们这些创业者和个人开发者量身打造的AI服务落地利器。许多AI工程项目,我们只需去构造好自己的训练集和测试集,其余的模型训练、推理、部署,Amazon SageMaker 都能够帮我们轻松完成。
本次博文所分享的 Stable Diffusion 2.0,通过参考官方提供的技术文档,只用了 20分钟左右的时间,我就在Amazon SageMaker 上成功搭建了一套流畅的AI绘画在线服务,接下来,让我们一起揭秘。
借助 Amazon SageMaker 进行环境搭建和模型推理
1. 创建 jupyter notebook 运行环境
- 点击链接登录至亚马逊云科技管理控制台
在搜索框中搜索 SageMaker ,如下图所示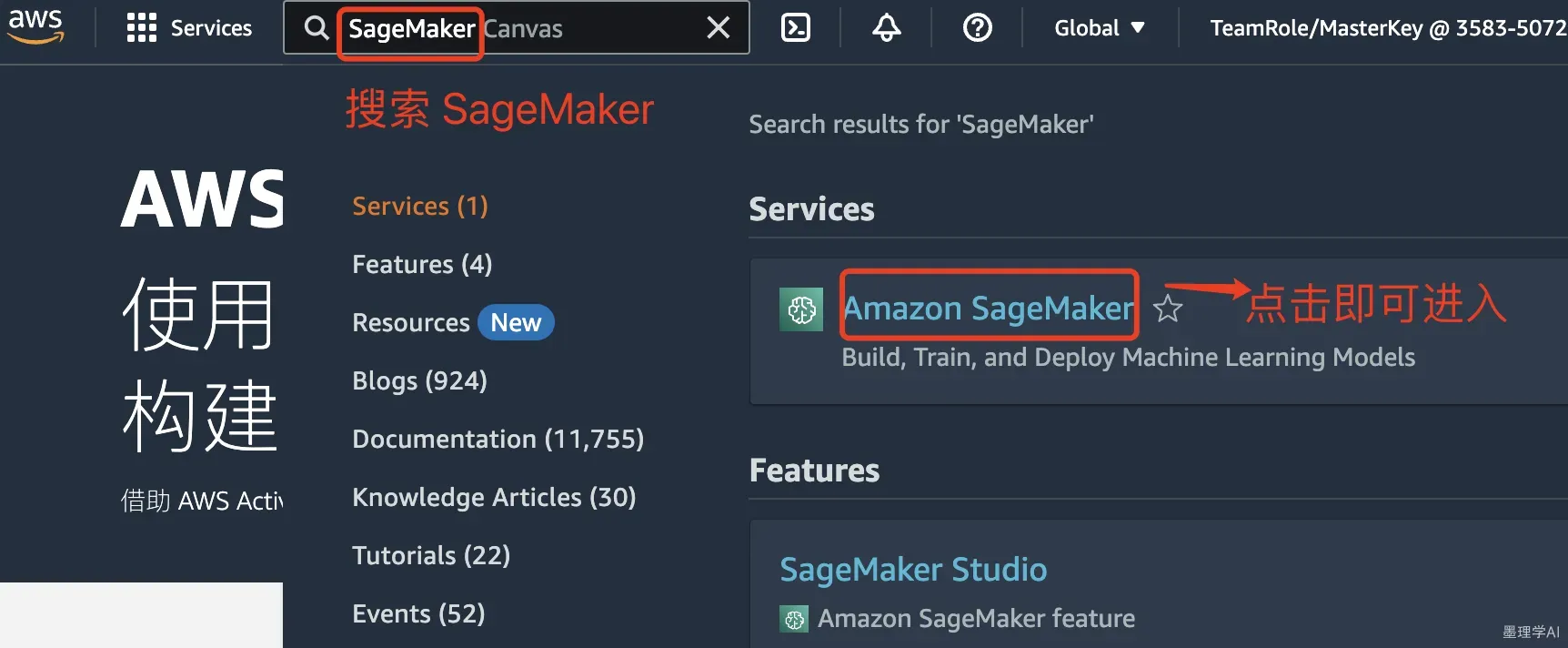
这里我们创建一个笔记本编程实例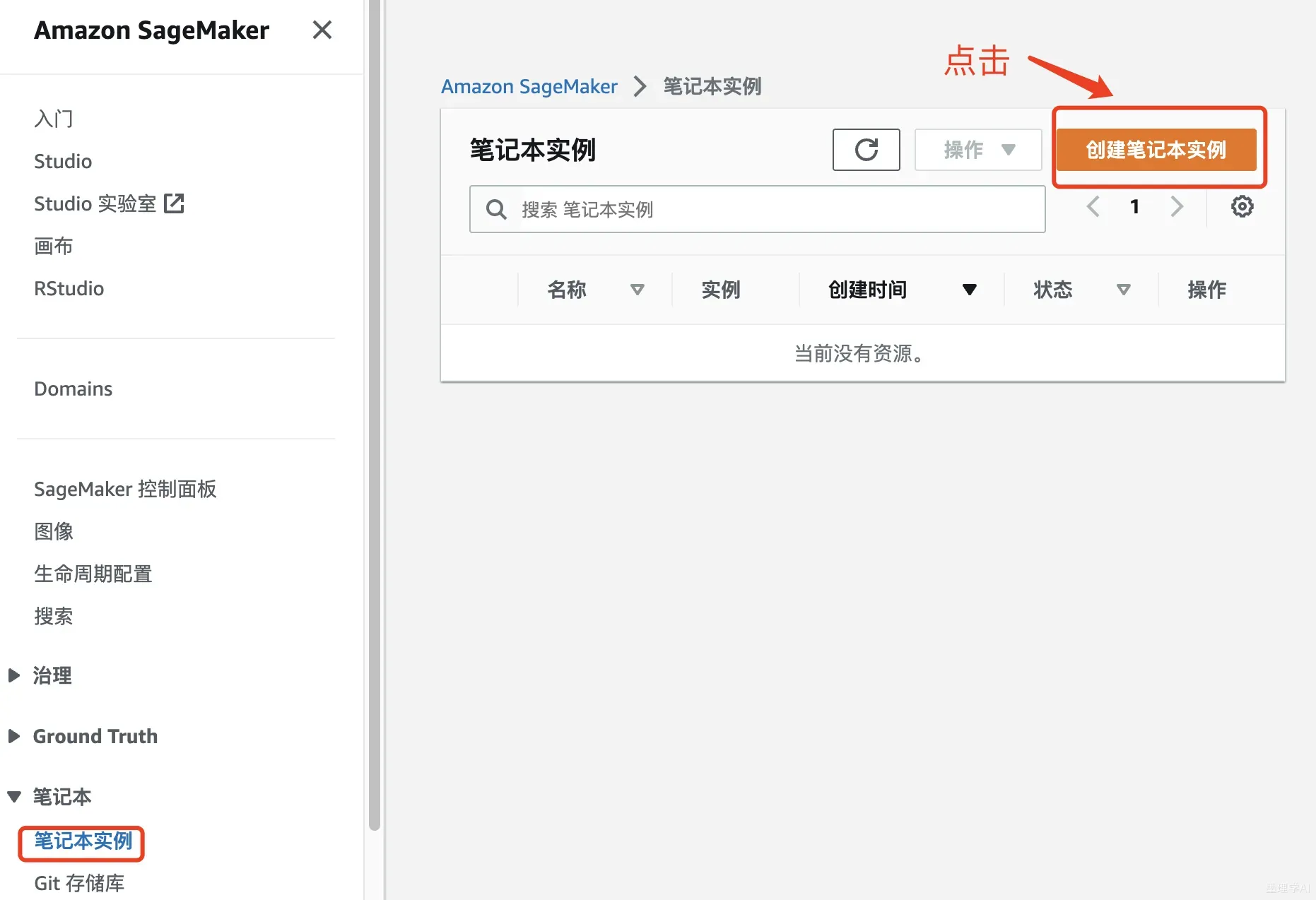
我这里选择的配置如下: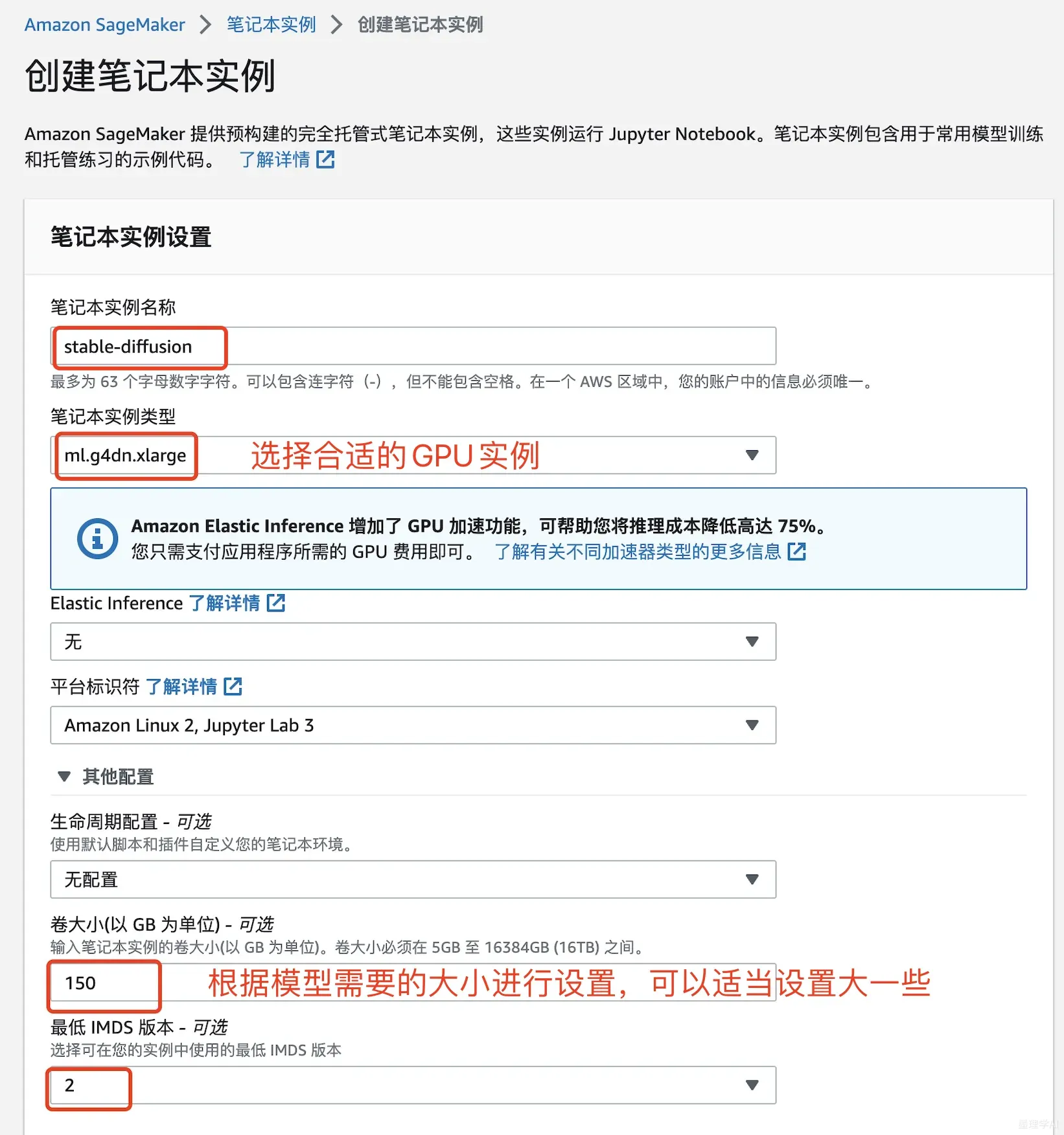
选择角色,其他的默认即可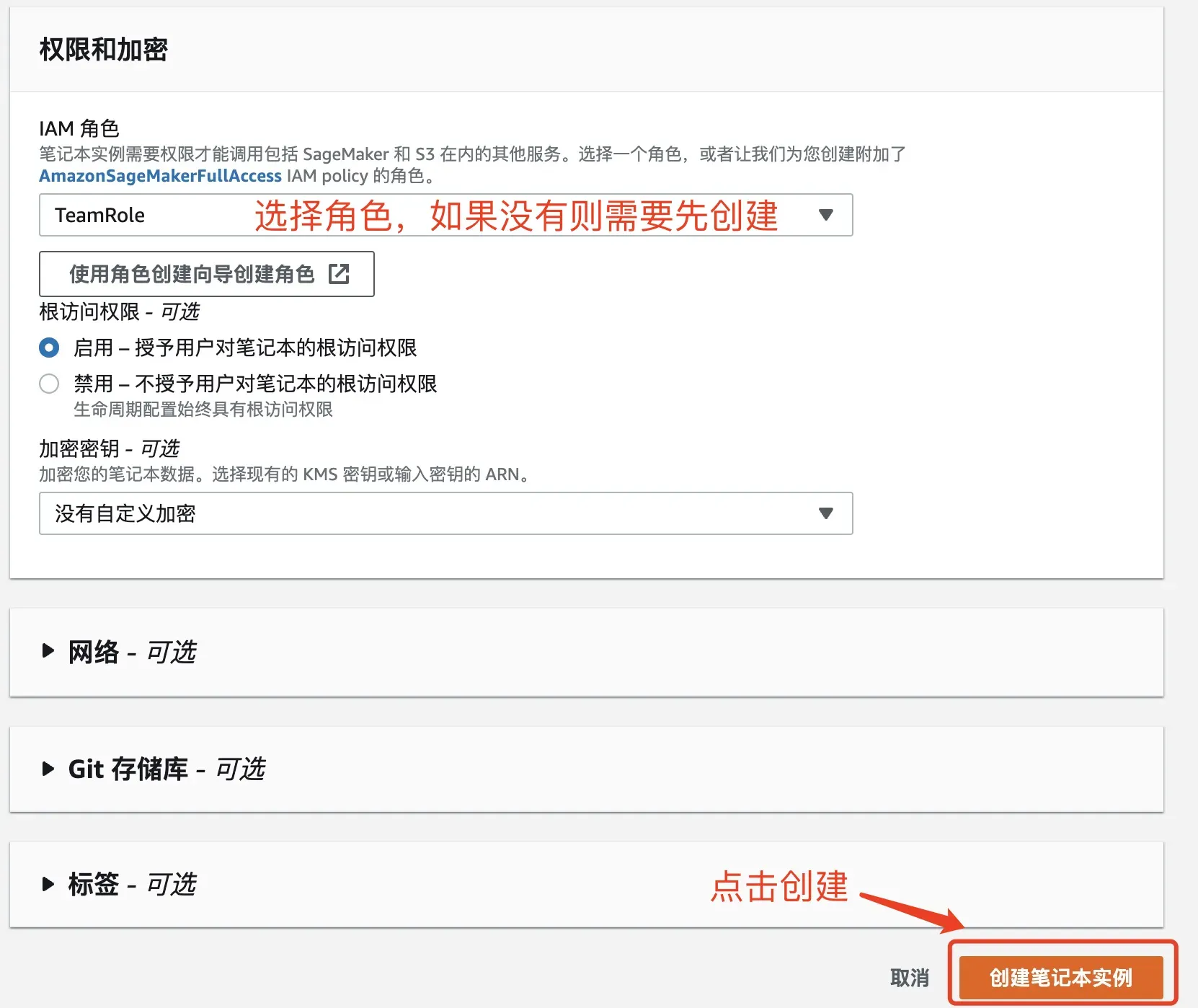
大概5分钟左右,实例就创建成功啦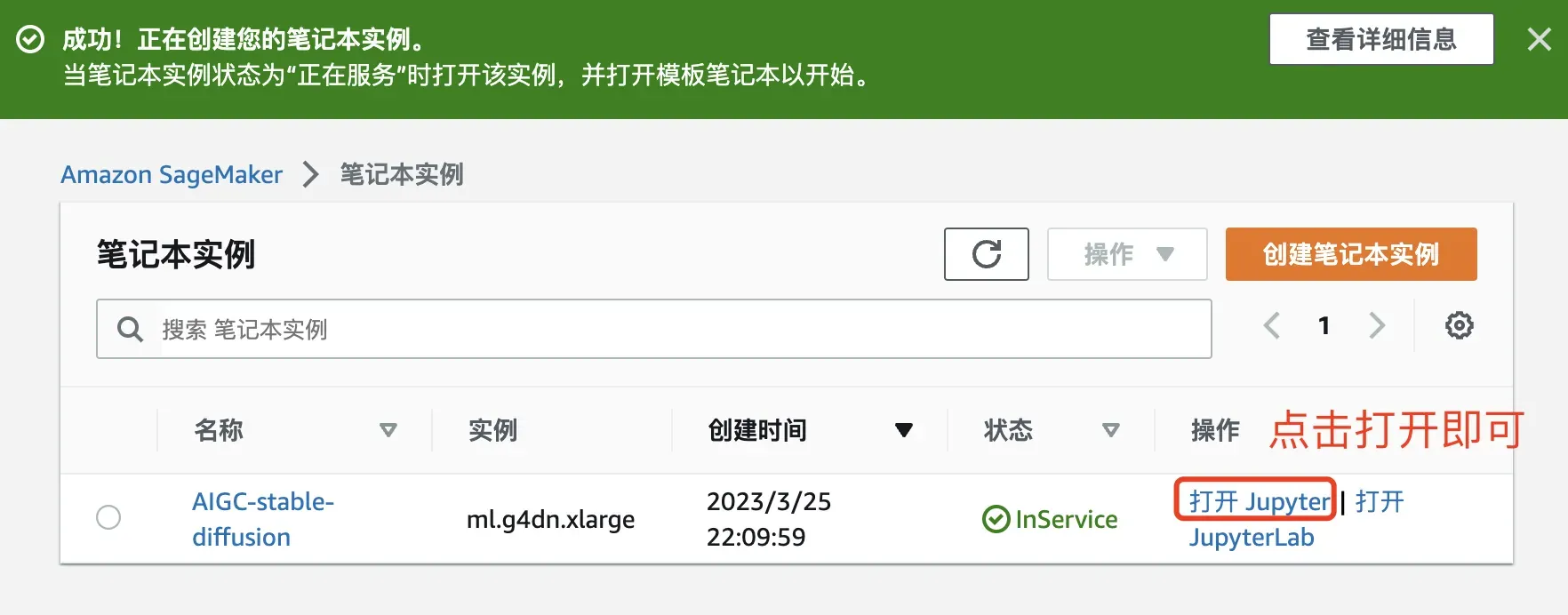
- 点击链接,下载代码
上传刚刚下载的代码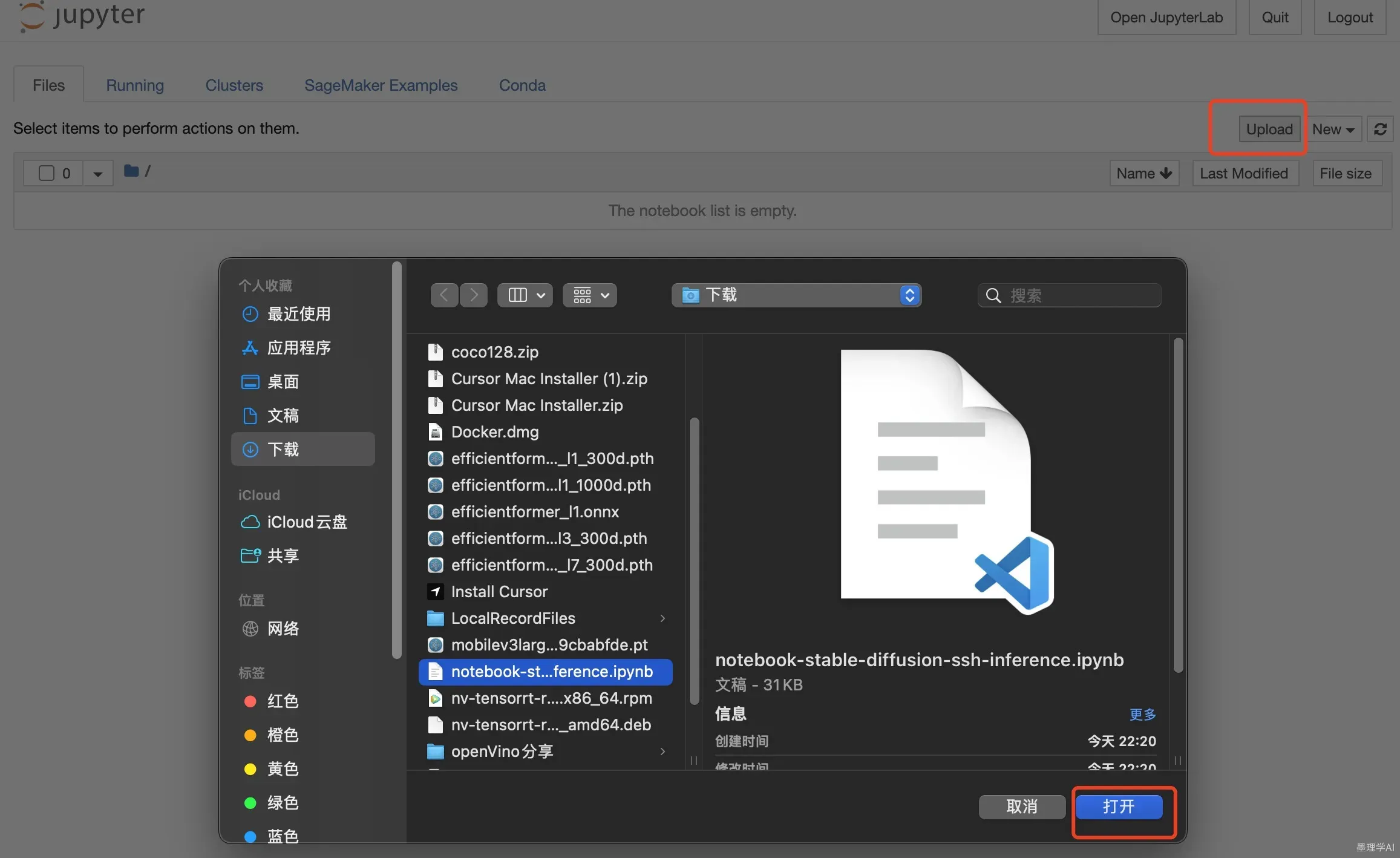
直接打开这个代码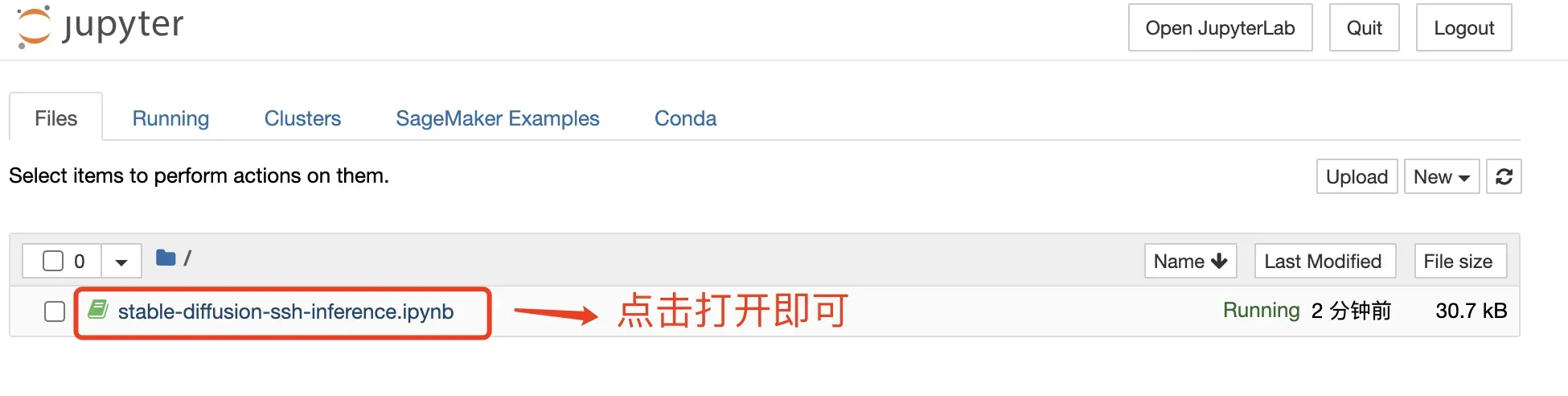
选择合适的conda环境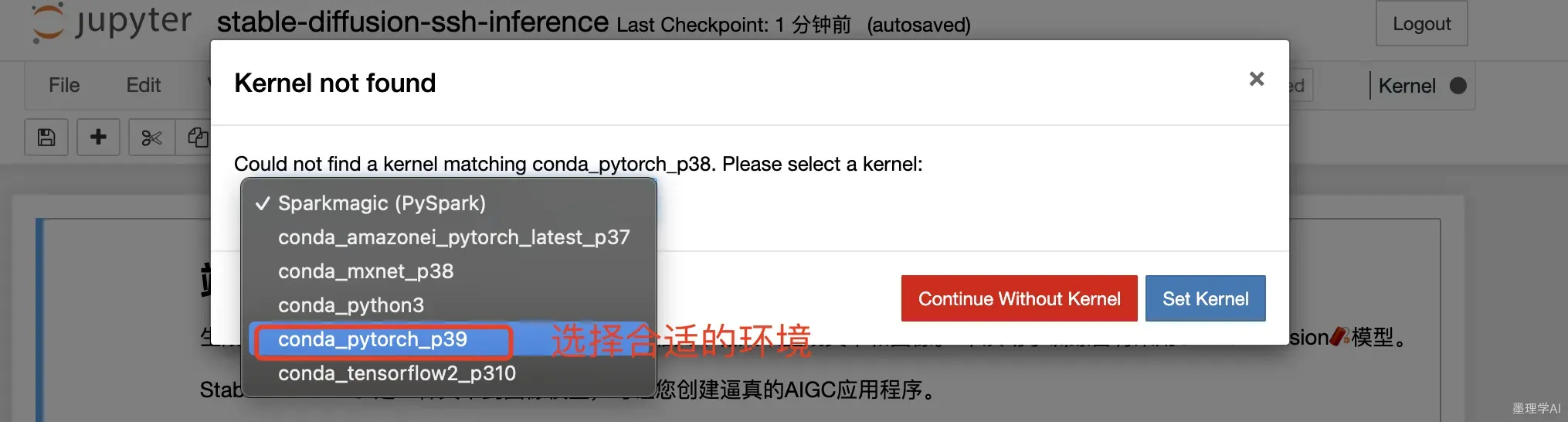
2. 一键运行所有代码
这里我们直接一键运行运行所有代码即可,代码执行过程中会依次完成 Stable Diffusion 模型相关类和函数的代码定义、推理测试,并打包代码和模型,然后部署模型至Sagemaker 推理终端节点 (PS:这里的所有代码运行完毕大概需要5到10分钟左右)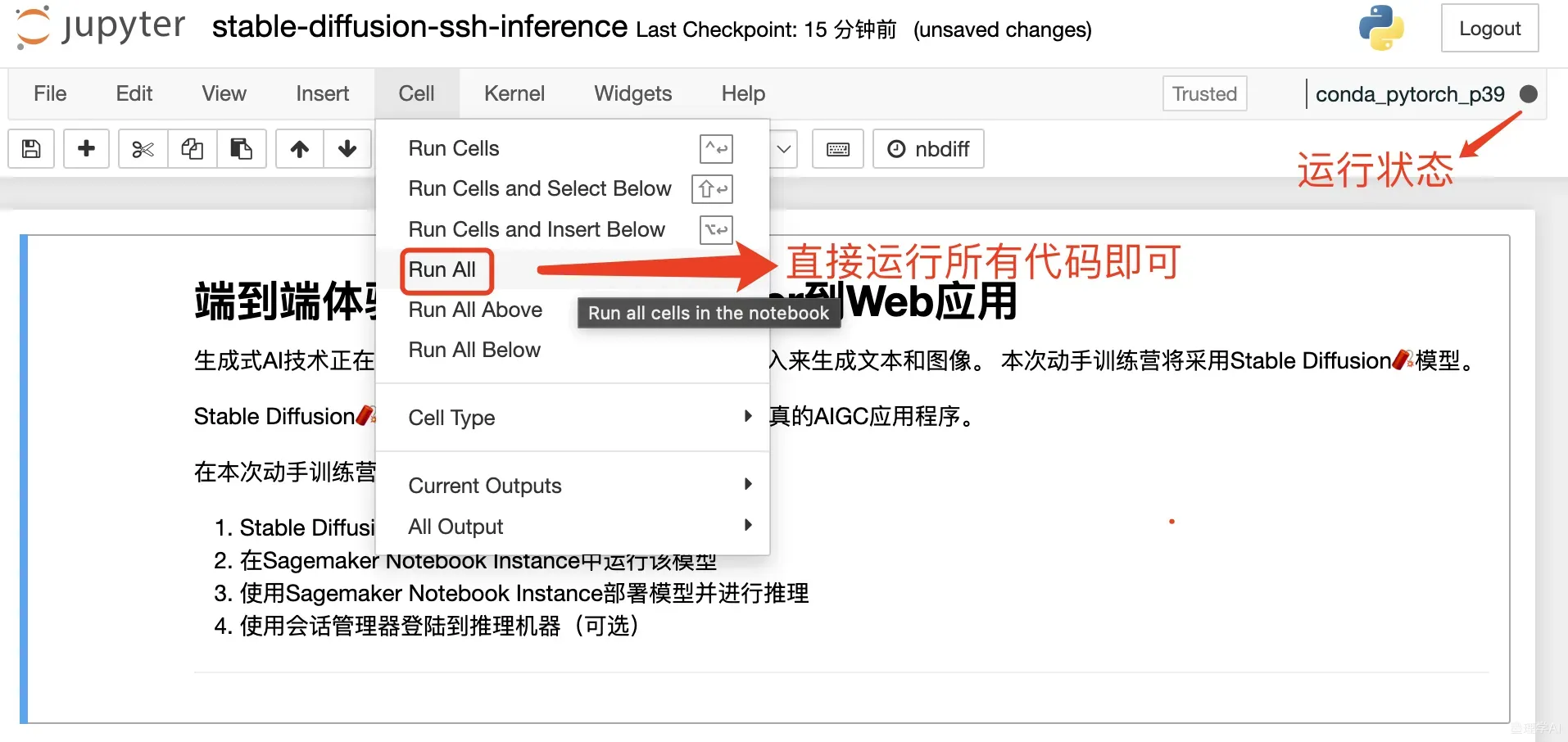
关键代码分析如下
1. 环境准备,代码模型下载
检查当前 pyTorch 版本
1 | |
Bash
Copy
安装 Stable Diffusion 代码运行额外需要的依赖库,这网速飞快
1 | |
Bash
Copy
下载代码和模型文件,这里直接下载Hugging Face提供的代码和模型即可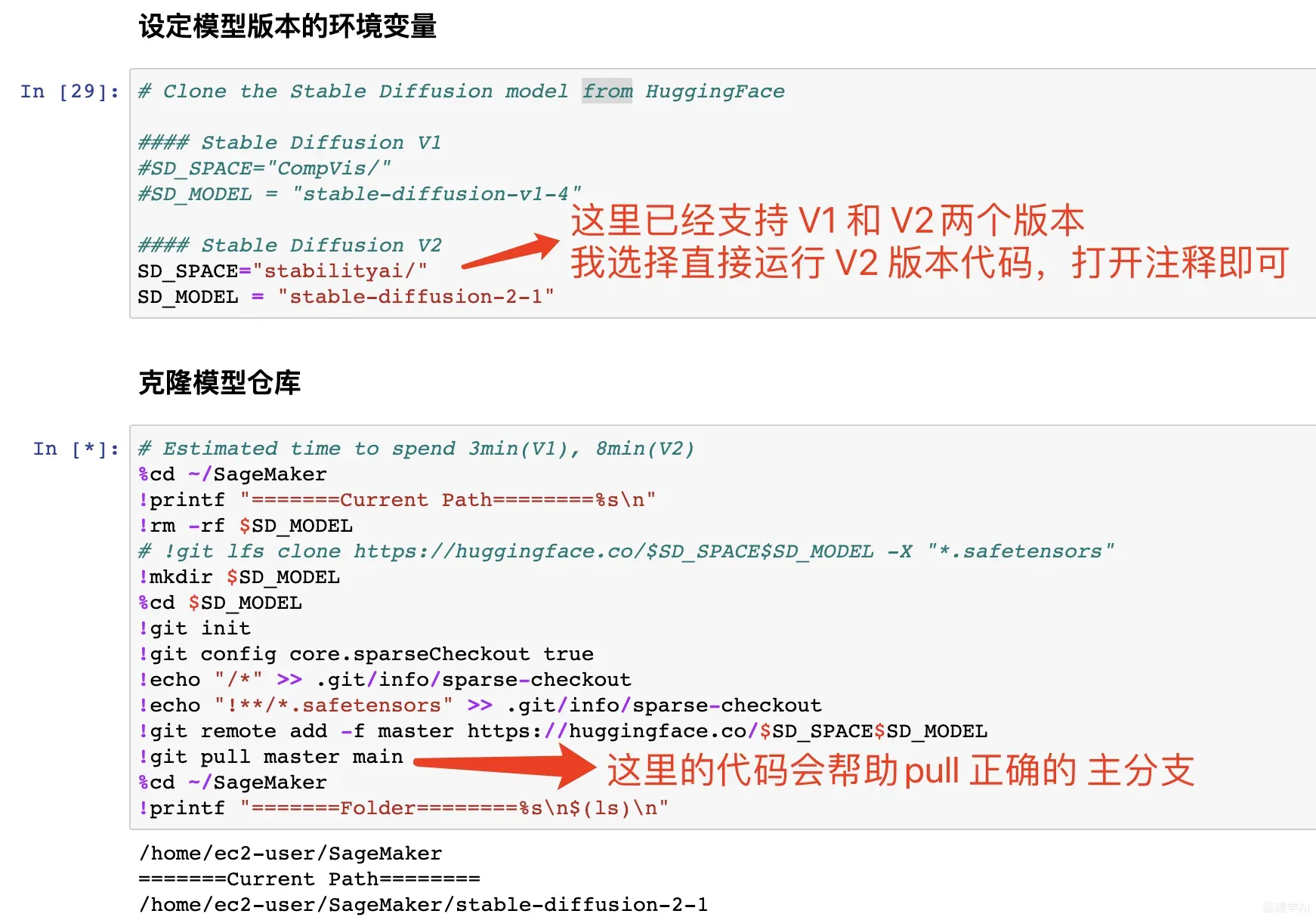
2. 在Notebook中配置并使用模型
直接调用 函数进行模型加载
1 | |
Python
Copy
在 Cuda 上进行模型的推理,这里 Stable Diffusion V2 能够支持生成的最大图像尺寸为 768 * 768
1 | |
Bash
Copy
友情提示 :如果报错,遇到推理时 GPU 内存不够,则可以尝试以下三种方式进行解决
- 试一试生成分辨率小一点的图片
- 减少生成图片的数量
- 升级机型,选择更强的GPU服务器
3. 部署模型至Sagemaker 推理终端节点
我们这里直接使用 AWS 的 SageMaker Python 开发工具包部署模型刚刚已经验证能够运行成功的模型和打包好的代码。
- 编写初始化的Sagemaker代码用于部署推理终端节点
1 | |
Python
Copy
- 创建 inference.py 脚本,进行模型的加载和推理
1 | |
Python
Copy
在 Amazon Cloud9 创建前后端 Web 应用
AWS Cloud9 是一种基于云的集成开发环境 (IDE),只需要一个浏览器,即可编写、运行和调试代码。包括一个代码编辑器、调试程序和终端,并且预封装了适用于 JavaScript、Python、PHP 等常见编程语言的基本工具,无需安装文件或配置开发计算机,即可开始新的项目。
- 这里我直接参考官方提供的手册,跟着操作即可完成 Web 服务的部署
1. 创建云服务实例,并进行web环境安装
这里我试用了 Cloud9 云服务,在查找服务处搜索 Cloud9,并点击进入Cloud9服务面板即可
点击创建环境
我这里的设置如下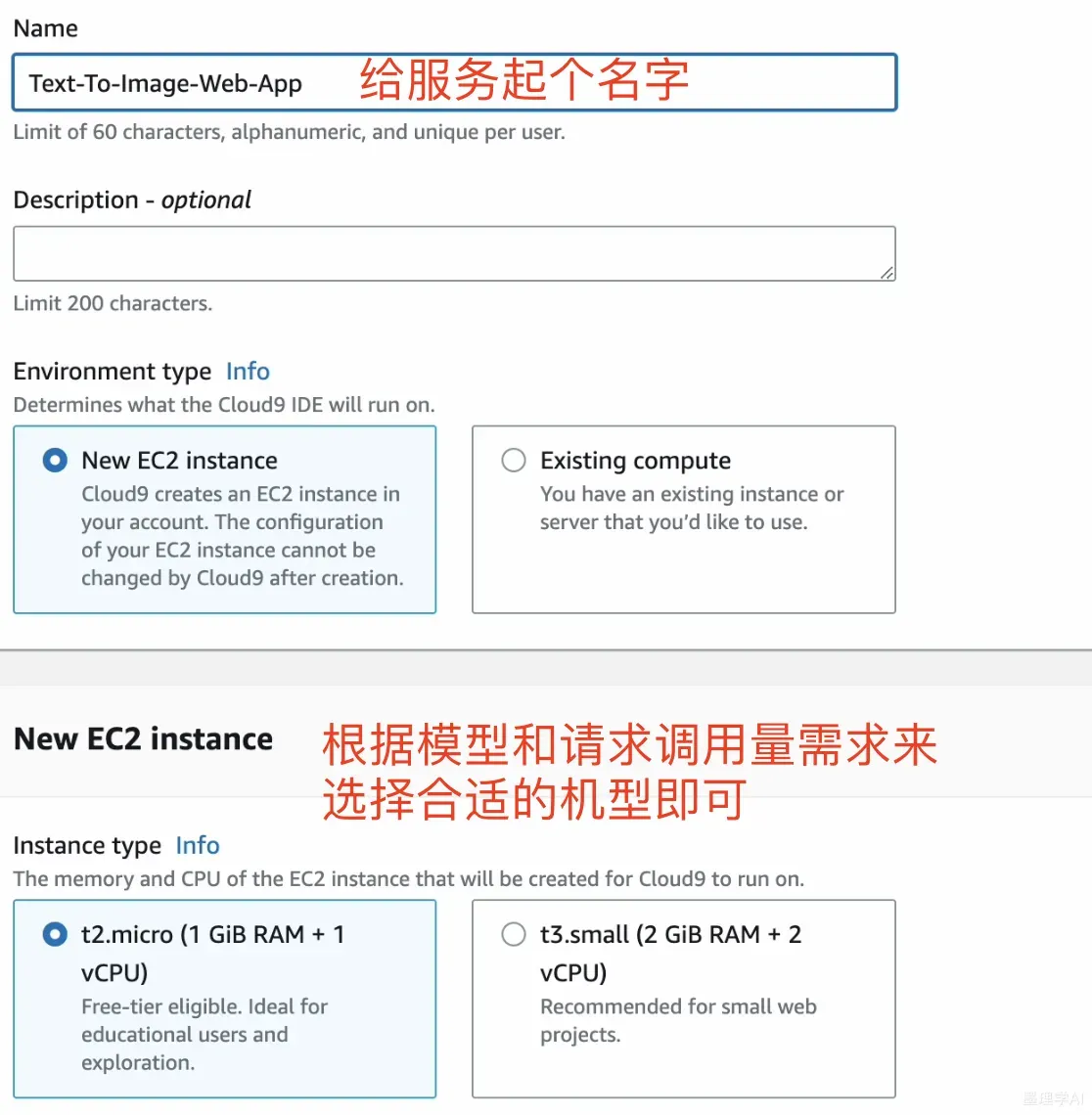
其他部分配置保持默认,在页面底部点击橙色的 Create 按钮创建环境。 环境的创建将花费1-2分钟的时间。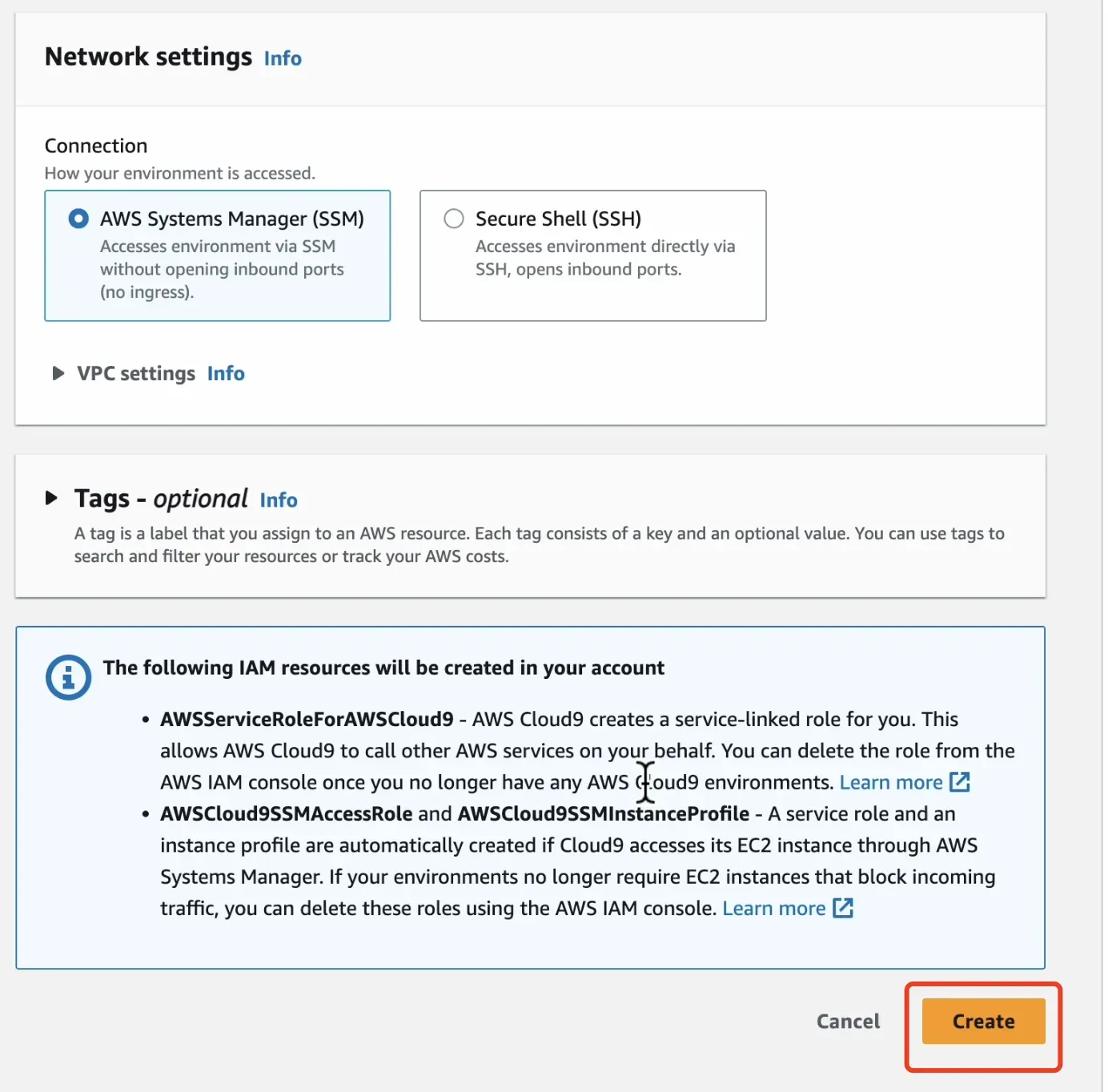
创建成功之后,点击 open 进入服务控制台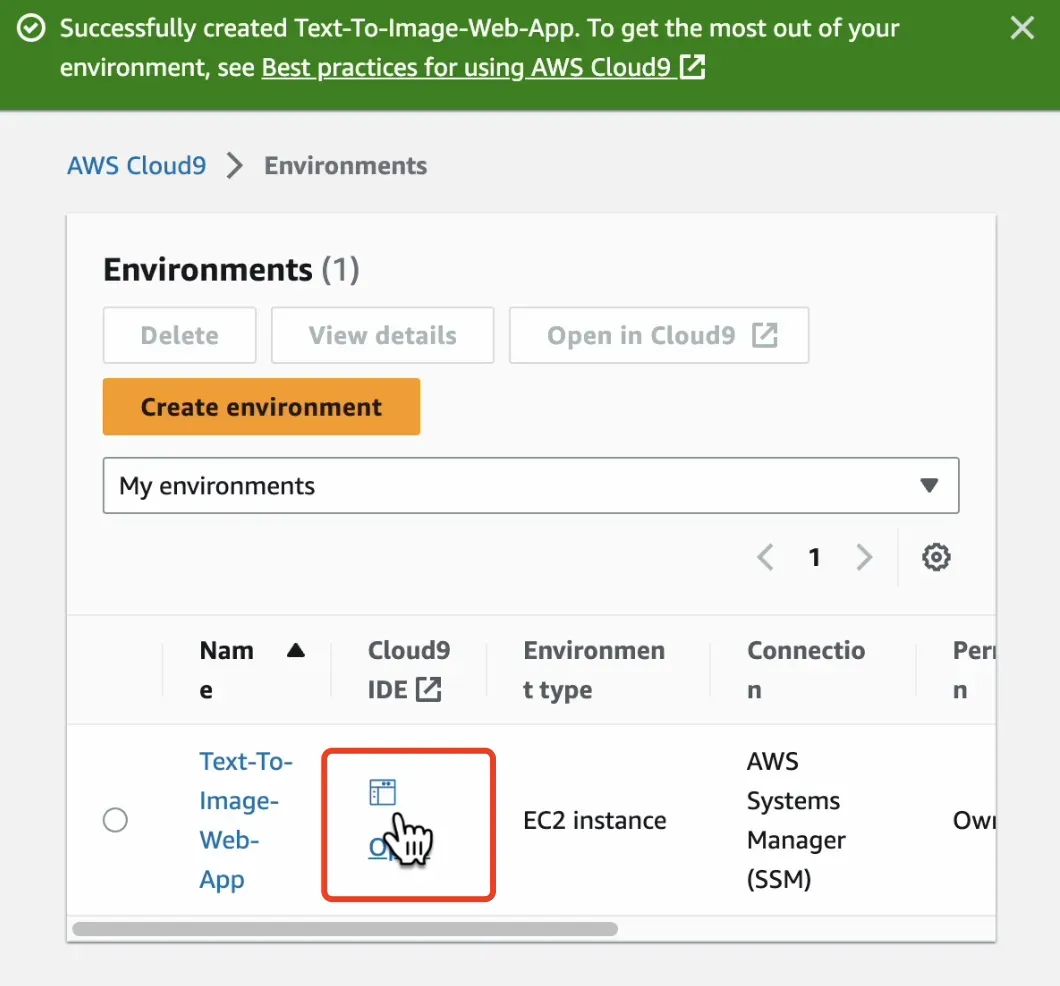
粘贴左侧的代码,复制到控制台bash窗口进行运行,会自动下载和解压代码
1 | |
Bash
Copy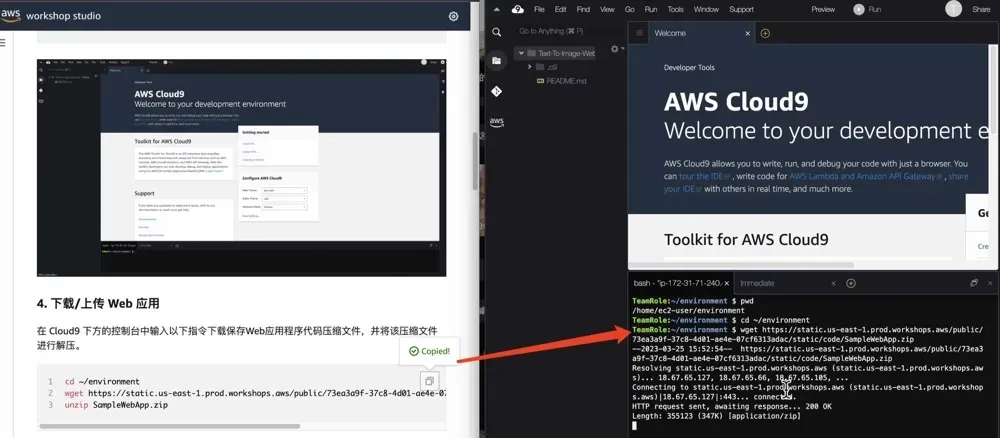
2. 运行启动web服务,输入想要生成的图像参数和提示词,调用推理服务
依赖的环境安装好之后,就可以运行这个服务代码
服务启动成功之后,访问 127.0.0.1:8080 即可访问本地服务;设定 width 和 Length 参数,以及想要生成的图片描述,然后点击提交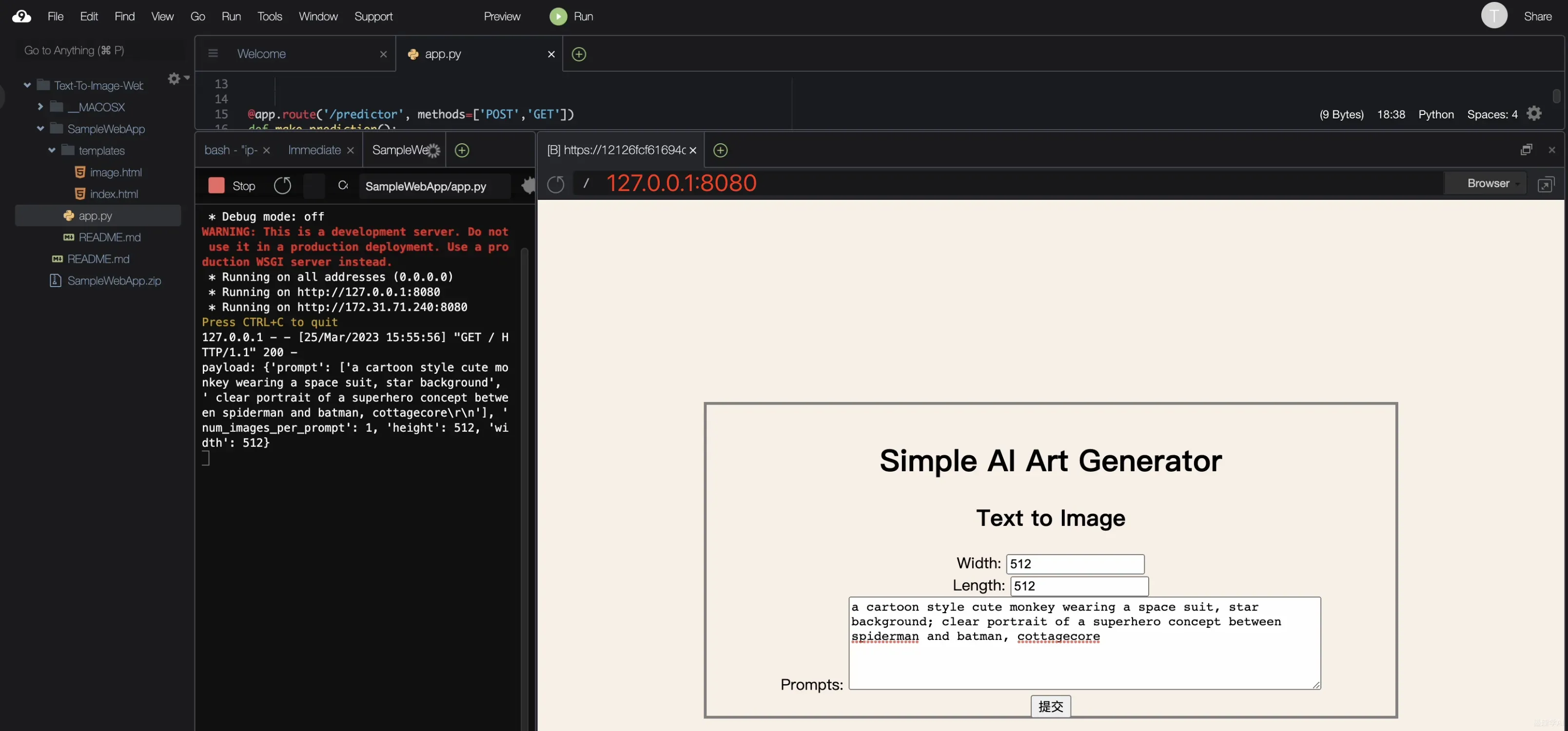
等待 几秒钟之后,就得到了上面输入的两个 提示词对应生成的图像,看得出来效果还是非常不错的;
- 经测试发现,即使每次输入的提示词是同一个,模型生成得到的输出也是不固定的
- 输入的提示词语越精准,生成的图像效果会容易越好
- 基于亚马逊SageMaker服务平台,如此快速(熟练之后,不到半个小时)就能搭建好一套AI模型的web端在线推理调用,果然好的技术就是第一生产力
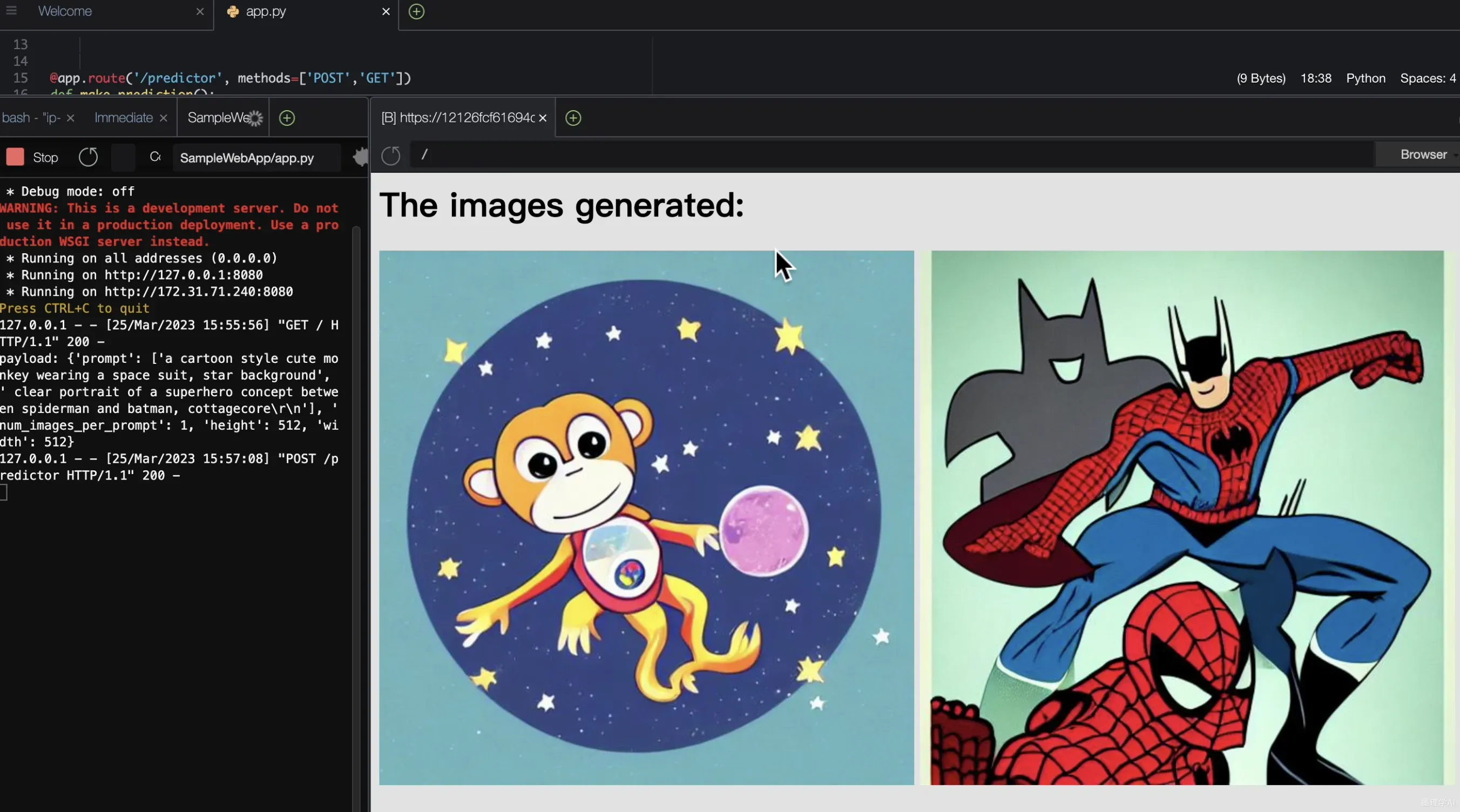
3. 文本图像生成示例
Stable Diffusion 对提示词有着非常高的要求,你输入的提示词越详细,能够让模型理解的越好,那么生成的图像内容就会越贴近预期,生成质量越好;
这里提供3组文本图像生成的示例,方便各位同学参考:
| 提示词 | 生成图像示例1 | 生成图像示例2 |
|---|---|---|
| A rabbit is piloting a spaceship |  |
 |
| Driverless car speeds through the desert |  |
 |
| A small cabin on top of a snowy mountain in the style of Disney, artstation |  |
 |